11. 객체지향 쿼리 언어(2) - JPQL 정리
JPQL
- JPQL은 객체지향 쿼리 언어
- 테이블이 아닌 엔티티 객체를 대상으로 쿼리함
- JPQL은 SQL을 추상화해서 특정 데이터베이스에 의존하지 않음
JPQL은 결국 SQL로 변환됨
- 기본 문법과 쿼리 API
SELECT,UPDATE,DELETE문 사용 가능. INSERT의 경우 em.persist()를 사용하면 되므로 없음select_문:: = select_절 from_절 [where_절] [groupby_절] [having_절] [orderby_절] update_문:: = update_절 [where_절] delete_문:: = delete_절 [where_절]- SELECT 문
Select m FROM Member AS m where m.username = 'Hello'- 대소문자 구분
- 엔티티와 속성은 대소문자를 구분함 (Member, member)
- JPQL 키워드는 대소문자 구분을 하지 않음 (SELECT, FROM)
- 엔티티 이름
- JPQL에서 사용한 Member는 클래스 명이 아닌 엔티티 명
- 엔티티 명은 @Entity(name = “XXX”) 어노테이션으로 지정될 수 있음
- 별칭은 필수
- JPQL은 별칭을 필수로 사용해야 함(e.g. Member as m)
- TypeQuery, Query
- TypeQuery : 반환 타입이 명확할 때 사용
- Query : 반환 타입이 명확하지 않을 때 사용
- em.createQuery() 메소드의 두 번째 인자에 반환 타입을 지정하면 TypeQuery를 반환하고, 지정하지 않으면 Query를 반환
//TypeQuery 사용 TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class); List<Member> resultList = query.getResultList();// Query 사용 Query query = em.createQuery("SELECT m FROM Member m"); List resultList = query.getResultList();
- 결과 조회
- query.getResultList() : 결과를 리스트로 반환, 결과가 없으면 빈 컬렉션 반환
- query.getSingleResult() : 결과가 정확히 하나일 때 사용
- 결과가 없으면 javax.persistence.NoResultException 예외 발생
- 결과가 1개보다 많으면 javax.persistence.NonUniqueResultException 예외 발생
파라미터 바인딩 JDBC는 위치 기준 파라미터 바인딩만 지원, JPQL은 이름 기준 파라미터 바인딩도 지원
- 이름 기준 파라미터(Named parameters)
- 파라미터를 이름으로 구분하는 방법
String usernameParam = "User1"; TypedQuery<Member> query = em.createQuery("SELECT m FROM MEMBER m where m.username = :username", Member.class); query.setParameter("username", usernameParam); List<Member> result = query.getResultList();
- 위치 기준 파라미터(Positional parameters)
- ? 다음에 위치 값을 주면 됨
List<Member> members = em.createQuery("SELECT m FROM Member m WHERE m.username =?1", Member.class); .setParameter(1, usernameParam); getResultList();
- 파라미터 바인딩이 아닌 String concatenation을 할 경우
- SQL 인젝션 같은 공격이 가능
- 컴파일된 SQL 재사용 불가능
- 이름 기준 파라미터(Named parameters)
- 프로젝션
- SELECT 절에 조회할 대상을 지정하는 것
- SELECT [프로젝션 대상] FROM …
- 엔티티 프로젝션
- 엔티티 자체를 조회하는 것
- 조회하면 영속성 컨텍스트에서 관리됨
SELECT m FROM Member m SELECT m.team FROM Member m
- 임베디드 타입 프로젝션
- 임베디드 타입은 조회의 시작점이 될 수 없음(아래처럼 사용 불가)
String query = "SELECT a FROM Address a";- 아래처럼 엔티티를 통해 임베디드 타입을 조회해야 함
String query = "SELECT o.address FROM Order o"; List<Address> addresses = em.createQuery(query, Address.class) .getResultList();- 임베디드 타입은 엔티티 타입이 아닌 값 타입, 따라서 영속성 컨텍스트에서 관리되지 않음
- 스칼라 타입 프로젝션
- 스칼라 타입 : 숫자, 날짜, 문자와 같은 기본 데이터 타입들
- 예를들어 전체 회원의 이름을 조회한다면?
String query = "SELECT username FROM Member m"; List<String> usernames = em.createQuery(query, String.class) .getResultList(); // 중복 데이터 제거 // SELECT DISTINCT username FROM Member m
- 여러 값 조회
- 엔티티 단위가 아닌 필요한 데이터만 선택해서 조회할 때
- Query 사용, TypeQuery는 사용 불가
Query query = em.createQuery("SELECT m.username, m.age FROM Member m"); List resultList = query.getResultList(); for(Object[] row : resultList){ // row[0] : uesrname // row[1] : age }
- new 명령어로 조회
- 위에 코드에서는 바로 Object로 받아서 처리했지만 실제 애플리케이션에서는 DTO 사용
- SELECT 다음에 NEW 연산자와 반환받을 클래스를 지정해주면 해당 클래스 생성자에 JPQL 조회 결과를 바로 넘겨줄 수 있음
TypedQuery<UserDTO> query = em.createQuery("SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m"); List<UserDTO> resultList = query.getResultList();- new 명령어 사용 시 주의사항
- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다
- 순서와 타입이 일치하는 생성자가 필요하다
- 페이징 API
- 데이터베이스마다 페이징을 처리하는 문법이 다름
- JPA에서는 페이징을 다음 두 API로 추상화
setFirstResult(int startPoisition: 조회 시작 위치(0부터 시작)setMaxResults(int maxResult: 조회할 데이터 수
TypedQuery query = em.createQuery("SELECT m FROM Member m ORDER BY m.username DESC"); query.setFirstResult(10); query.setMaxResults(20); query.getResultList();
- 집합과 정렬
- 집합 함수
- COUNT : 결과 수를 구함, Long 타입 반환
- MAX, MIN : 최대, 최소 값 구함, 문자 숫자 날짜 등에 사용
- AVG : 평균값을 구함, 숫자타입만 사용 가능, Double 타입 반환
- SUM : 합을 구함, 숫자타입만 사용 가능
- NULL 타입은 무시하므로 통계에 잡히지 않음
- DISTINCT를 같이 이용하면 중복된 값을 제외하고 집합을 구할 수잇음
- GROUP BY, HAVING
- GROUP BY
- 통계를 구할 때 특정 그룹끼리 묶어줌
- 예를들어 팀 이름으로 묶고싶을 땐
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age) from Member m LEFT JOIN m.team t GROUP BY t.name
- HAVING
- GROUP BY와 함께 사용하며 그룹화한 통계 데이터를 기준으로 필터링할 때 사용
- 예를들어 위에서 그룹화 한 것들 중 평균 나이가 10살 이상을 조회할 때/
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age) from Member m LEFT JOIN m.team t GROUP BY t.name HAVING AVG(m.age) >= 10
- GROUP BY
- 정렬 (ORDER BY)
- ASC : 오름차순(default)
- DESC : 내림차순
select t.name, COUNT(m.age) as cnt from Member m LEFT JOIN m.team t GROUP BY t.name ORDER BY cnt DESC
- 집합 함수
- 경로 표현식
- .(점)을 찍어서 객체 그래프를 탐색하는 것
- 상태 필드(state field) : 단순히 값을 저장하기 위한 필드
- 연관 필드(association field) : 연관관계를 위한 필드
- 단일 값 연관 필드 : @ManyToOne, @OneToOne, 대상이 엔티티 (e.g. m.team)
- 컬렉션 값 연관 필드 : @OneToMany, @ManyToMany, 대상이 컬렉션(e.g. m.orders)
@Column(name = "name") private String name; // 상태 필드 private Integer age; // 상태 필드 @ManyToOne(..) private Team tea; // 연관 필드(단일 값) @OneToMany(..) private List<Order> orders; // 연관 필드(컬렉션 값)- 경로 표현식의 특징
- 상태 필드 경로 : 경로 탐색의 끝으로 더 탐색이 불가능함
- 단일 값 연관 경로 : 묵시적으로 내부 조인 발생, 계속 탐색이 가능함
- 컬렉션 값 연관 경로 : 묵시적으로 내부 조인 발생, 더 탐색이 불가능함. 단 FROM 절에서 조인을 통해 별칭을 얻을 경우 탐색 가능
- 경로 표현식 사용 주의 사항
- 묵시적 조인은 항상 내부 조인
- 컬렉션은 경로 탐색의 끝. 컬렉션에서 경로 탐색을 하려면 명시적으로 조인해서 별칭을 얻어야 함
- 조인은 SQL 튜닝에 주요 포인트임
- 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어려움
- 따라서 가급적 묵시적 조인 대신에 명시적 조인 사용
- 서브 쿼리
- JPQL도 SQL과 같이 서브 쿼리를 지원함 (WHERE, HAVING 절에서만, 하이버네이트는 SELECT 절에서도 가능)
select m from Member m where m.age > (select avg(m2.age) from Member m2)- 서브 쿼리 함수
- EXISTS
- 문법 : [ NOT ] EXISTS (subquery)
- 설명 : 서브쿼리에 결과가 존재하면 참(NOT은 반대)
select m from Member m where exists (select t from m.team t where t.name = '팀A')
- {ALL or ANY or SOME}
- 문법 : {ALL or ANY or SOME} (subquery)
- 설명 : 비교 연산자와 같이 사용함
- ALL은 모두 만족했을 때, ANY와 SOME은 만족하는게 하나라도 있을 때
-- 전체 상품 각각의 재고보다 주문량이 많은 주문들을 조회 select o from Order o where o.orderAmount > ALL (select p.stockAmount from Product p) -- 어떤 팀이든 팀에 소속된 회원 select m from Member m where m.team = ANY (select t from Team t)
- IN
- 문법 : [ NOT ] IN (subquery)
- 설명 : 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
-- 20세 이상을 보유한 팀 select t from Team t where t IN (select t2 From Team t2 JOIN t2.members m2 where m2.age >= 20)
- EXISTS
- 조건식
- 타입 표현
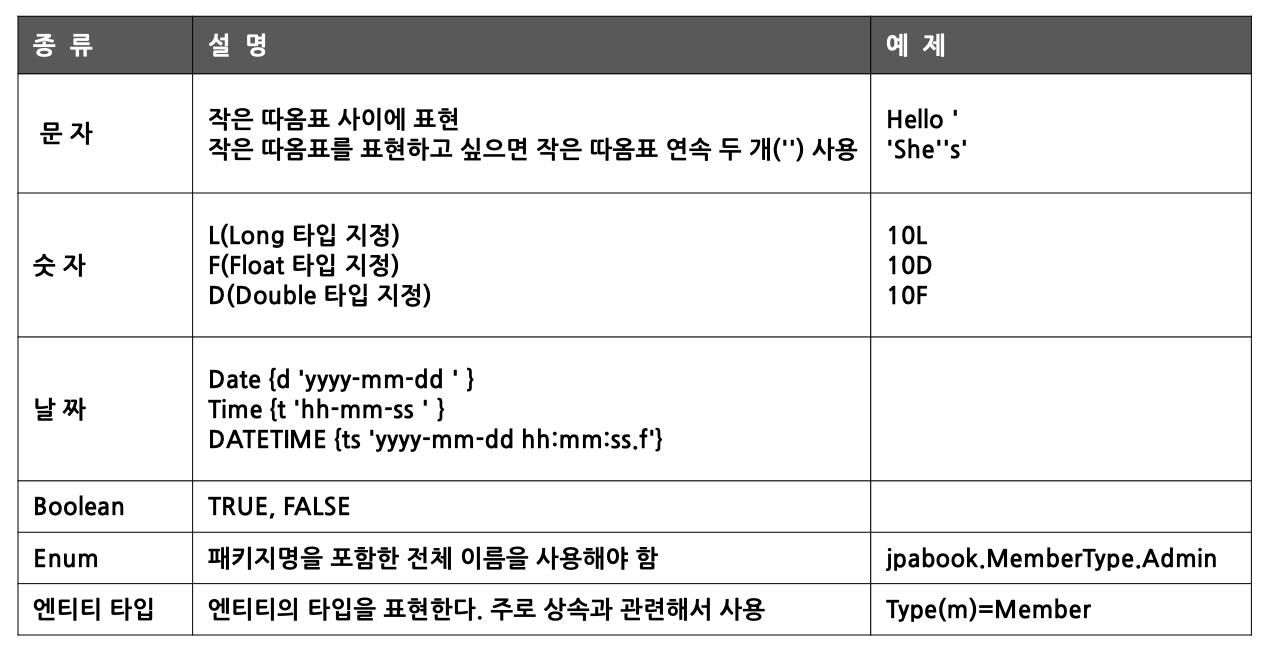
- CASE 식
- 기본 CASE 식 : 컨디션에 대한 조건
select case when m.age <= 10 then '학생요금' when m.age >= 60 then '경로요금' else '일반요금' end from Member m
- 단순 CASE 식 : 정확한 매칭 조건
select case t.name when '팀A' then '인센티브110%' when '팀B' then '인센티브120%' else '인센티브105%' end from Team t
- COALESCE : 하나씩 조회해서 null이 아니면 반환
-- 사용자 이름이 없으면 이름 없는 회원을 반환 select coalesce(m.username, '이름 없는 회원') from Member m
- NULLIF : 두 값이 같으면 null 반환, 다르면 첫번째 값 반환
-- 사용자 이름이 '관리자'면 null을 반환하고 나머지는 본인의 이름을 반환 select coalesce(m.username, '이름 없는 회원') from Member m
- 기본 CASE 식 : 컨디션에 대한 조건
- Named 쿼리 : 정적 쿼리
- JPQL의 쿼리 타입?
- 동적 쿼리 : em.createQuery()와 같이 런타임에 구성되는 쿼리
- 정적 쿼리 : 미리 정의한 쿼리에 이름을 부여해서 사용, 한 번 정의되면 변경할 수 없음
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크하고 미리 파싱함
- 오류 확인이 빠르고 미리 파싱해두기 때문에 성능상 이점
- @NamedQuery 어노테이션 사용 (어노테이션이 아닌 XML에 정의하는 방법도 있음)
@Entity @NamedQuery( name = "Member.findByUserName", query = "select m from Member m where m.username = :username" ) public class Member { ... } ... List<Member> resultList = em.createQuery("Member.findByUserName", Member.class) .setParameter("username", "회원1") .getResultList();
- JPQL의 쿼리 타입?
- SELECT 절에 조회할 대상을 지정하는 것
