[Uptime Kuma] Custom Script 기반 Health Check 구현기
in Dev / Monitoring on Uptime-kuma, Healthcheck, DevOps, Monitoring
최근 사내 모니터링 시스템을 구축하면서 Uptime Kuma를 도입했다. 하지만 사용하다 보니 단순히 “서버가 떠있는지”를 확인하는 것을 넘어, “API가 올바른 데이터를 내려주는지” 검증해야 하는 요구사항이 생겼다.
이 과정에서 겪은 고민과, 결국 기능을 직접 구현하게 된 과정을 정리해본다.
1. Uptime Kuma를 선택했지만, 2% 부족했다
먼저 모니터링 도구로 오픈소스인 Uptime Kuma를 선택한 이유는 명확했다.
- (무료) Self-hosted: 내부망에 있는 서비스를 모니터링해야 했고, 비용 부담 없이 구축할 수 있다.
- 직관적인 UI: 별도의 학습 없이도 대시보드 구성이 가능하다.
하지만 본격적으로 API Health Check를 설정하려다 보니 한계에 봉착했다. 내가 원한 것은 단순한 200 OK 확인이 아니라, 응답 데이터의 정합성(Context) 을 검증하는 것이었다.
- “응답 배열(
items)의 길이가 0보다 커야 한다.” (데이터 누락 체크) - “
status가SUCCESS일 때만data필드가 존재해야 한다.” (값 간의 의존성) - “특정 날짜 필드가 유효한 포맷이어야 한다.”
기존 Uptime Kuma의 기본 모니터들로는 이런 동적 로직을 처리하기 어려웠다.
2. 기존 기능으로 해결해보려 했다 (시도와 한계)
처음에는 기능을 확장하기보다, 이미 있는 기능들을 최대한 활용해보려 했다.
2.1. HTTP Keyword Monitor
가장 단순한 방법이다. 응답 본문에 특정 문자열(예: "status":"OK")이 포함되어 있는지 확인한다.
- 한계: 단순 포함 여부만 알 수 있다. JSON 구조를 이해하지 못하므로, 정교한 검증은 불가능하다.
2.2. JSON Query Monitor
JSONPath를 사용해서 특정 필드 값을 추출하고 기대값과 비교하는 방식이다.
- 한계: 정적인 값 비교에는 훌륭하지만, 로직을 넣을 수는 없다. “배열의 길이가 5 이상인가?”, “A값이 B값보다 큰가?” 같은 조건은 JSONPath만으로는 표현하기 어렵다.
2.3. Push Monitor
별도의 Python이나 Shell 스크립트로 검증 로직을 짜서 Cron으로 돌리고, 성공 시 Uptime Kuma에 신호(Heartbeat)를 보내는 방식이다.
- 한계: 관리 포인트가 쪼개진다. 모니터링 툴(Kuma)과 검증 스크립트(Crontab/Lambda)를 따로 관리해야 한다. 스크립트가 죽었는지 감시하는 또 다른 모니터링이 필요해지는 아이러니가 발생한다.
3. 나만 불편한가? (Maintainer의 거절)
“분명 나랑 비슷한 니즈를 가진 사람들이 있을 텐데?” 싶어 Github Issue를 뒤져보았다. 역시나 스크립트 기반 모니터링(Exec Monitor)에 대한 요청은 예전부터 꾸준히 있었다.
Feature Request: Exec monitor / Script monitor
관련 이슈: https://github.com/louislam/uptime-kuma/issues/1117
사용자가 작성한 Shell script나 명령어를 실행해서 그 Exit Code로 상태를 판단하게 해달라는 요청이었다. 하지만 메인테이너는 이에 대해 부정적이다.
이유는 보안(Security) 때문이다. 웹 인터페이스를 통해 서버에서 임의의 코드를 실행(RCE)할 수 있게 열어두는 것은 보안상 매우 위험하기 때문이다. 만약 누군가 대시보드 권한을 탈취한다면, 서버 전체를 장악할 수 있게 된다.
4. 그래서 직접 만들었습니다 (Custom Script Monitor)
보안 우려는 타당하지만, 우리 환경은 사내 내부망 내에서 제한된 관리자만 접근하는 환경이었다. 보안 리스크보다는 통합된 모니터링 환경이 주는 생산성이 더 중요하다고 판단했다.
그래서 Node.js의 vm 모듈을 사용하여 격리된 환경(Sandbox)에서 사용자 스크립트를 실행하는 커스텀 모니터(json-javascript)를 직접 구현했다.
구현 방식
단순 new Function 대신 vm.runInContext를 사용했다. 사용자가 작성한 스크립트는 evaluate라는 함수를 정의해야 하며, 이 함수는 JSON 파싱된 응답 데이터(data)를 인자로 받아 { success: boolean, message: string } 형태의 객체를 반환해야 한다.
실제 server/model/monitor.js에 추가한 핵심 로직은 다음과 같다.
// server/model/monitor.js (Actual Implementation)
const vm = require("vm");
// ... (중략) ...
} else if (this.type === "json-javascript") {
let data = res.data;
// 1. JSON Parsing
if (typeof data === "string" && res.headers["content-type"] !== "application/json") {
try {
data = JSON.parse(data);
} catch (_) {
throw new Error(bean.msg + ", failed to parse json response");
}
}
// 2. Prepare Sandbox & Script
// 사용자가 입력한 코드 뒤에 'evaluate;'를 붙여서 함수 자체를 리턴받는다.
let evaluator = `${this.jsonJavascript}\nevaluate;`;
let sandbox = { console }; // console 로그는 허용
let context = vm.createContext(sandbox);
try {
let script = new vm.Script(evaluator);
let evaluateFunction = script.runInContext(context); // Sandbox 내에서 실행
// 3. Execute User Function
let result = evaluateFunction(data);
// 4. Validate Result
if (result?.success) {
bean.msg += ", result of custom script is true";
bean.status = UP;
} else {
throw new Error(bean.msg + "," + result?.message);
}
} catch (e) {
console.log(e.message);
throw e;
}
}
이렇게 구현하면 사용자는 Uptime Kuma UI에서 다음과 같이 스크립트를 작성하여 정교한 검증을 할 수 있다.
// 사용자가 입력하는 스크립트 예시
function evaluate(data) {
if (data.items.length === 0) {
return { success: false, message: "Items array is empty" };
}
if (data.status !== "SUCCESS") {
return { success: false, message: "Status is not SUCCESS" };
}
return { success: true };
}
이제 복잡한 로직이 필요해도 관리 포인트가 늘어나지 않고 Kuma 안에서 해결된다.
나름 기존 UI와 최대한 일치하도록 구현했다. 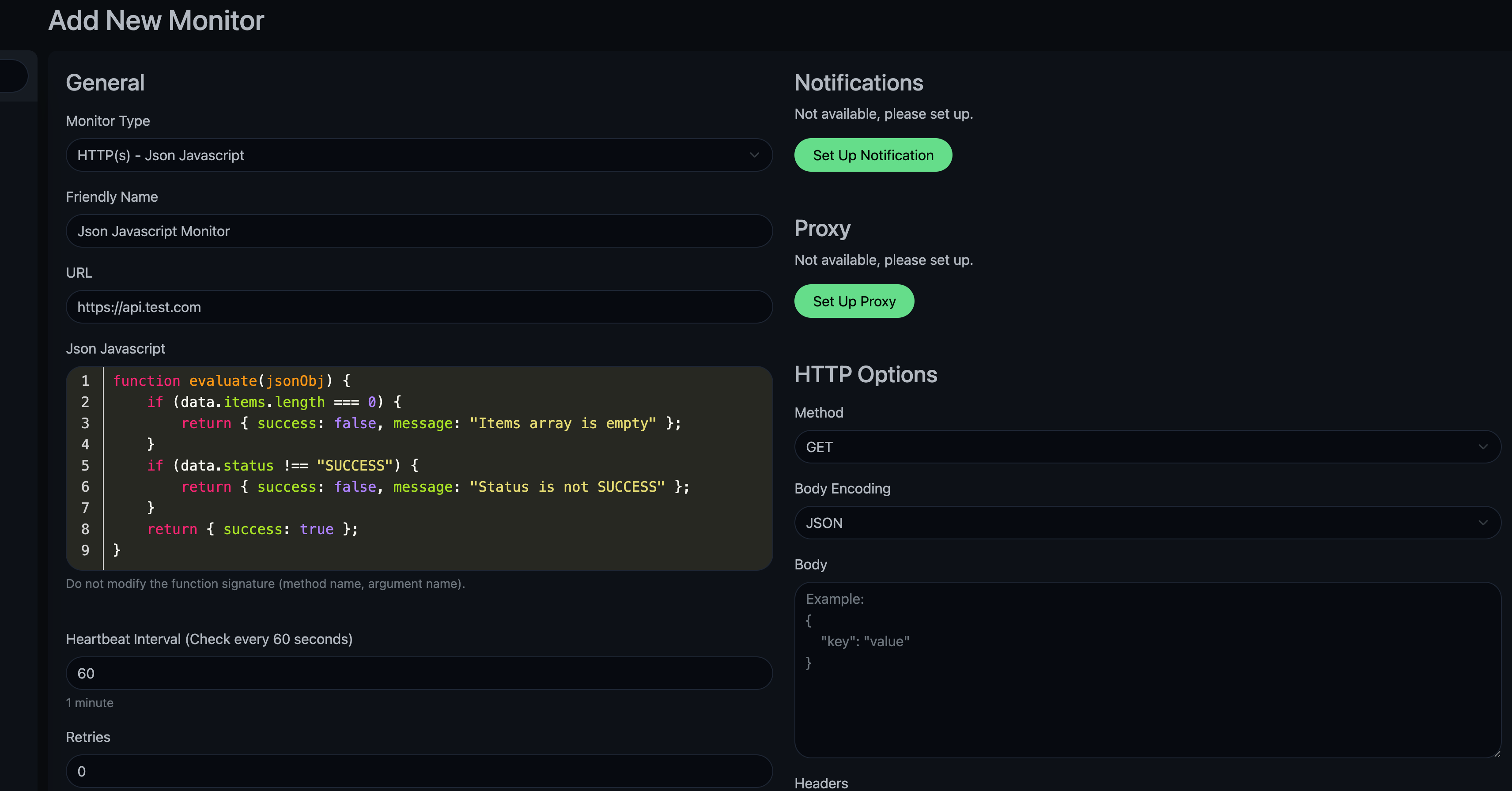
5. 회고: 과연 이것이 최선이었을까?
기능을 구현하고 실제 운영에 적용해보니 확실히 편리함은 있었다.
단순히 “서버가 200 OK를 뱉는다”는 것만으로는 알 수 없는, DB 데이터가 비어있거나 특정 비즈니스 로직이 오작동하는 상황을 Uptime Kuma라는 단일 대시보드에서 즉각 감지할 수 있었기 때문이다.
하지만 마음 한구석에는 여전히 “이게 정말 맞는 방법인가?” 라는 의문이 남아있다.
- 관심사의 분리: “헬스 체크 툴이 비즈니스 로직의 정합성까지 검증하는 게 맞나?” 너무 많은 책임을 모니터링 도구에 지우는 것은 아닐까?
- 유지보수: API 응답 스펙이 변경될 때마다 모니터링 스크립트도 수정해야 한다. 결국 모니터링 코드가 애플리케이션 코드와 강하게 결합(Coupling)되는 결과를 낳았다.
물론 현재의 사내 내부망 환경과 리소스 제약 속에서는 이것이 가장 현실적이고 효율적인 대안 이었다고 생각한다. 덕분에 운영 안정성이 크게 높아진 것도 사실이다.
하지만 만약 리소스가 충분했다면 별도의 테스트 자동화 파이프라인이나 전문적인 Observability 도구를 도입하는 게 더 깔끔한 아키텍처가 아니었을까 하는 아쉬움은 남는다. 앞으로도 “운영의 편의성”과 “아키텍처의 순수성” 사이에서 끊임없이 줄타기를 하며 더 나은 정답을 찾아봐야겠다.
혹시 이 글을 읽고 비슷한 고민을 하고 계시거나, 직접 적용해보고 싶으신 분들은 아래 PR의 코드를 참고하셔도 좋습니다.
