Spring WebFlux: Blocking vs Non-Blocking In-Memory Cache 성능 비교 실험
in Java / Spring / Webflux on Java, Springboot, Webflux, Caching, Ehcache, Caffeine, Performance
1. 배경: Spring Boot 2.x와 커스텀 캐싱
사내에서 Spring Boot 2.x 기반의 WebFlux 애플리케이션을 운영하고 있었다. 당시 버전에서는 Mono나 Flux 같은 Reactive 타입에 대해 @Cacheable 어노테이션이 제대로 지원되지 않았다.
그래서 우리는 Map이나 Ehcache 같은 In-Memory 캐시를 사용하기 위해, AOP(@Aspect)를 직접 구현하여 캐싱 로직을 만들어 썼다.
기존 구현 방식 (Blocking)
@Around("@annotation(reactorCacheable)")
public Object cache(ProceedingJoinPoint joinPoint, ReactorCacheable reactorCacheable) throws Throwable {
String key = generateKey(joinPoint);
// 1. 캐시 조회 (Blocking)
// Ehcache의 get()은 동기 메서드이므로, 호출하는 스레드(Netty Event Loop)를 점유함
Object cachedValue = cacheManager.getCache(name).get(key);
if (cachedValue != null) {
return Mono.just(cachedValue);
}
// 2. 캐시 미스 시 실제 로직 수행 후 캐시 저장 (Blocking)
return ((Mono<?>) joinPoint.proceed()).doOnNext(value -> {
cacheManager.getCache(name).put(key, value);
});
}
당시에는 이 방식이 Blocking 방식이라는 사실조차 인지하지 못했다. “그냥 Ehcache가 빠르니까 괜찮겠지” 하고 별다른 의심 없이 사용해 왔다.
그러다 최근 Spring Boot 3(Spring Framework 6)로 업그레이드를 준비하면서 문서를 보게 되었는데, Spring 6부터 Caffeine 기반의 Async Caching이 공식 지원된다는 내용을 접하게 되었다. 기존 @Cacheable은 동기식 반환 타입을 전제로 설계되어 Mono/Flux를 제대로 지원하지 않았고, 새로운 방식은 CompletableFuture를 활용해 비동기적으로 동작한다는 설명이었다.
그제서야 깨달았다. “아, 우리가 지금 쓰고 있는 방식(Ehcache + 커스텀 AOP)은 사실상 동기(Blocking) 방식이었구나!”
자연스럽게 고민이 시작되었다.
“비동기 방식으로 변경하면 기존 대비 유의미한 성능 및 안정성 차이가 있을까?” “왜 금기시되는 Event Loop Blocking을 하고 있었는데도, 그동안 눈에 보이는 문제가 없었을까?”
이 궁금증을 해결하기 위해, 직접 k6와 Grafana를 이용해 실험을 진행해 보았다.
2. 실험 설계
비교군 설정
- WebFlux-Ehcache (Blocking): 기존 레거시 방식.
cache.get()을 Event Loop 위에서 직접 호출. - WebFlux-Cache (Non-Blocking): Spring Boot 3 + Caffeine (Async).
CompletableFuture기반의 비동기 방식으로 동작.
환경
- Kubernetes 환경에 파드 배포
- k6 부하 테스트 스크립트 (동시 접속자 100명)
- 캐시 미스 시 DB 조회를 시뮬레이션하기 위해
500ms지연을 강제로 주입
3. 실험 결과
시나리오 A: Cache Hit 100% (Read-Intensive)
캐시가 꽉 차있고, 모든 요청이 캐시에서 반환되는 상황이다.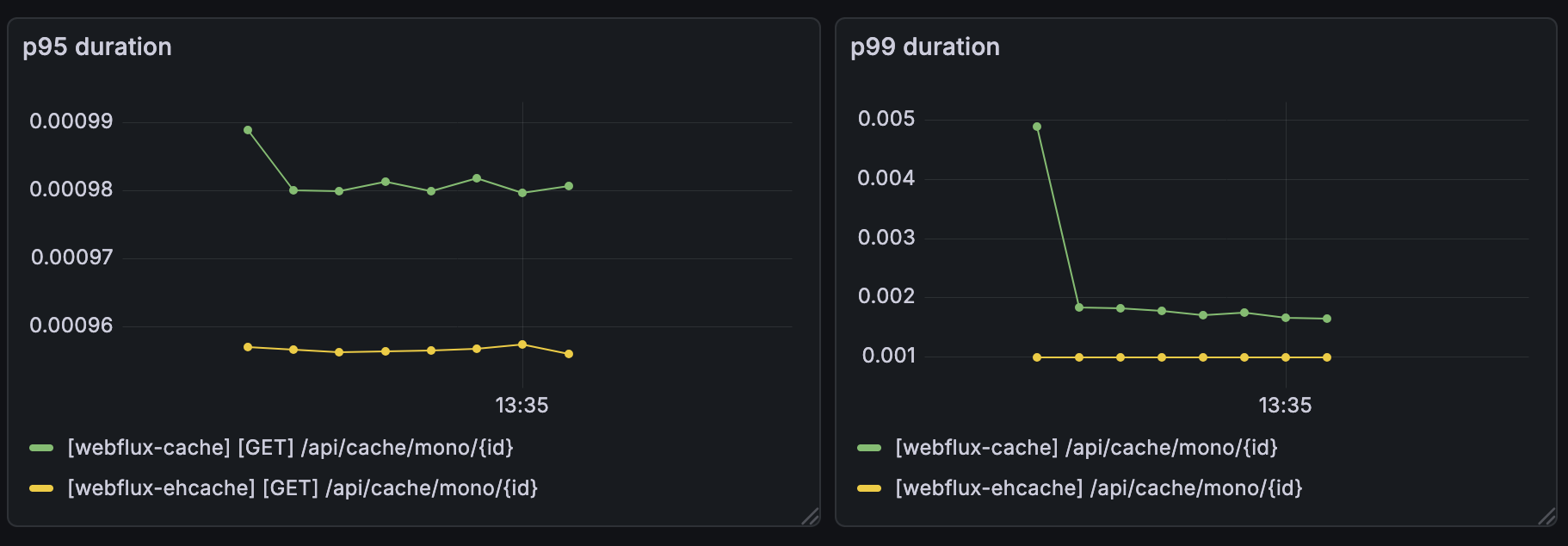
결과: 성능 차이가 거의 없었다. Netty Event Loop를 블로킹한다고 해서 걱정했는데, 응답 시간은 두 방식 모두 매우 빨랐다.
시나리오 B: Cache Hit 50% (Write-Intensive & Eviction)
키 범위를 늘려서 강제로 Cache Miss를 유발하고, put() 호출 빈도를 높여 쓰기 부하를 유도했다.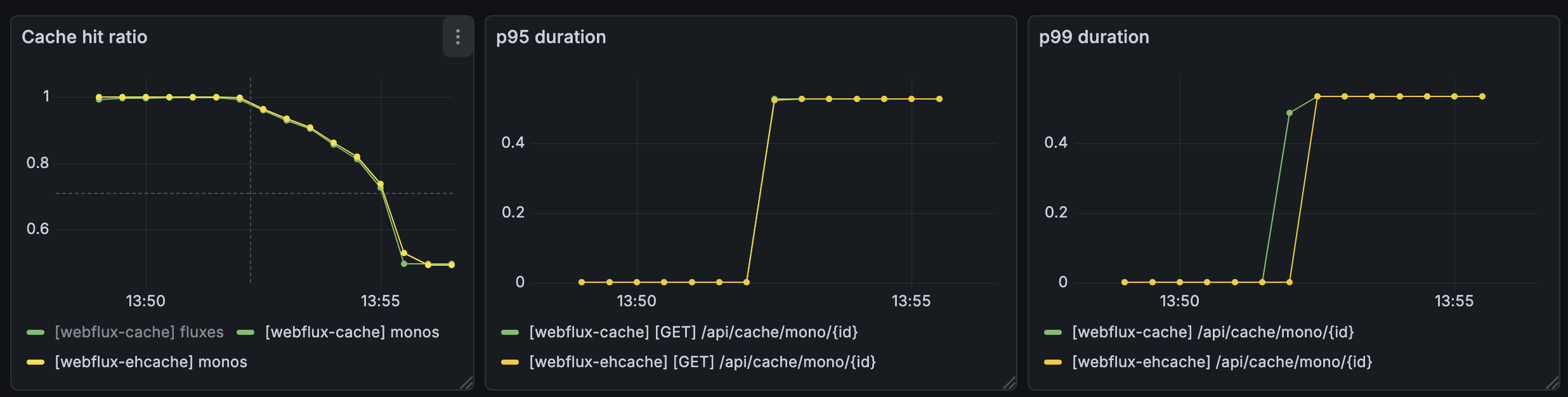
결과: 여전히 유의미한 성능 차이가 없었다. 캐시 미스 시 발생하는 500ms 지연이 그래프를 지배할 뿐, 캐시 라이브러리 차이로 인한 스파이크는 관찰되지 않았다. Blocking 방식에서도 Latency가 튀거나 처리량이 급락하는 현상은 없었다.
4. 왜 Blocking인데 느려지지 않았나?
실험 결과를 보고 나서야 이유를 알 수 있었다. 핵심은 “In-Memory(Heap) 캐시” 였기 때문이다.
1) 나노초(ns) 단위의 Blocking
Redis 같은 외부 저장소를 쓴다면 get() 한 번에 수 밀리초(ms)가 걸리고, 이는 Event Loop 입장에서 치명적이다. 하지만 Java Heap 메모리에 있는 데이터를 읽는 것은 수십 나노초(ns) 밖에 걸리지 않는다. WebFlux라 하더라도, 이 정도의 찰나의 시간 동안 스레드를 점유하는 것은 전체 처리량에 병목을 일으킬 정도가 아니었던 것이다.
2) 진짜 병목은 DB 조회 (500ms)
성능을 좌우하는 것은 캐시 라이브러리의 방식(Sync/Async)이 아니라, “캐시가 없을 때 DB를 다녀오는 시간” 이었다. 이번 실험에서는 DB 조회를 Mono.delayElement로 시뮬레이션하여 Non-Blocking으로 처리되었기 때문에, 캐시 자체의 오버헤드는 사실상 무시할 수 있는 수준이었다. 실제 서비스에서는 R2DBC 등 Non-Blocking DB 드라이버 사용 여부에 따라 결과가 달라질 수 있다.
5. 실험의 한계
이 실험 결과를 일반화하기 전에 아래와 같은 한계를 고려해야 한다.
- 동시 접속 규모: 실험의 동시 접속자 수는 100명이었다. 수천 명 이상의 동시 접속 환경에서는 나노초 단위의 블로킹이 누적되어 유의미한 차이가 발생할 수 있다.
- GC 영향: Heap 캐시의 크기가 매우 커지면 GC의 Stop-The-World가 Event Loop를 간접적으로 블로킹하는 영향도 고려해야 한다.
6. 결론
“In-Memory(Heap) 캐시라면 Blocking 방식을 써도 성능에 유의미한 악영향을 주지 않는다.”
메모리 접근 속도가 워낙 빠르기 때문에, Event Loop가 잠깐 멈추는 것이 전체 처리량에 큰 영향을 주지 않는다는 것이 증명되었다.
하지만 결론적으로 Spring Boot 3의 표준인 Async Caching(Caffeine)으로 전환하는 것을 권장한다.
- 표준 준수: 프레임워크가 권장하는 비동기 모델을 따르는 것이 장기적인 유지보수와 확장성에 유리하다.
- 잠재적 위험 제거: 혹여나 캐시 로직이 복잡해지거나(
Key생성이 무겁거나, 직렬화 비용 발생), 외부 저장소(Redis 등)로 변경될 경우, Blocking 방식은 언제든 시한폭탄이 될 수 있다.
“동작한다고 해서 그것이 최선은 아니다.”
이번 실험은 막연한 두려움 대신 데이터에 기반하여 기술을 검증하는 과정이었고, Blocking과 Non-Blocking의 비용 차이를 명확하게 이해하는 계기가 되었다. 특별한 이유가 없다면, WebFlux 환경에서는 비동기 표준을 따르는 것이 옳은 방향이라고 생각한다.
